
¿Qué es la Crawlability en SEO?
La crawlability es la capacidad de un sitio web para ser rastreado por los motores de búsqueda. Cuando los bots de Google y otros buscadores visitan una página, analizan su contenido y siguen los enlaces internos para descubrir nuevas URLs.
Si un sitio tiene una buena crawlability, significa que los motores de búsqueda pueden acceder fácilmente a sus páginas y comprender su estructura. En cambio, si hay problemas de rastreo, algunas páginas pueden quedar fuera del índice de Google, afectando su visibilidad en los resultados de búsqueda.
¿Cómo funciona el rastreo de los motores de búsqueda?

Los motores de búsqueda utilizan bots o crawlers para navegar por la web. Estos bots siguen los enlaces de una página a otra, recopilando información sobre cada URL que encuentran. El rastreo no es un proceso aleatorio. Está estructurado en tres etapas clave que determinan si una página será visible o ignorada por los buscadores:
1. Descubrimiento de URLs
En esta primera etapa, los motores de búsqueda deben descubrir nuevas páginas o identificar actualizaciones en las ya existentes. Esto lo hacen a través de:
- Enlaces internos: Los bots siguen los links que conectan distintas páginas dentro de un mismo sitio. Por eso, una buena arquitectura interna es clave para el SEO.
- Enlaces externos: Si otra web enlaza a una URL que aún no ha sido rastreada, el bot la encontrará al seguir ese enlace.
- Sitemaps XML: Son archivos que contienen un listado de URLs de un sitio, y se pueden enviar directamente a herramientas como Google Search Console para facilitar el descubrimiento.
- Archivos RSS o Atom: También ayudan a detectar cambios o publicaciones nuevas.
- Datos estructurados: Algunos tipos de markup permiten a los bots entender relaciones entre páginas y contenidos.
2. Rastreo del contenido
Una vez que se ha descubierto una URL, el crawler accede a la página para leer su contenido. En esta etapa:
- Se analiza el código HTML.
- Se examina la estructura de encabezados (H1, H2, etc.).
- Se identifican elementos multimedia (imágenes, videos), aunque estos a veces requieren procesamiento adicional.
- Se estudia el contenido textual, los enlaces, y metadatos como el <title> y las meta descripciones.
También se tienen en cuenta factores técnicos como:
- Velocidad de carga.
- Uso de JavaScript (algunos bots aún tienen limitaciones para interpretar JS).
- Restricciones en robots.txt.
- Etiquetas meta robots que indican si una página debe ser seguida o no.
Si el contenido es accesible, de calidad y no hay bloqueos técnicos, la página pasa a la siguiente etapa.
3. Indexación
No todas las páginas que se rastrean se indexan. En esta fase, el motor de búsqueda decide si almacenar la página en su índice, que es básicamente una gigantesca base de datos.
Una vez indexada, la página puede comenzar a aparecer en los resultados de búsqueda para consultas relevantes. Este paso depende de factores como:
- Relevancia del contenido.
- Originalidad y valor para el usuario.
- Ausencia de duplicidades.
- Optimización SEO on-page.
- Cumplimiento de directrices para webmasters.
🤷¿Qué impide que una página sea rastreada?
Aunque el proceso parezca simple, muchas páginas no llegan a ser indexadas debido a errores que afectan su rastreabilidad. Algunos de los más comunes son:
- Bloqueo en el archivo robots.txt: Este archivo puede impedir que los bots accedan a determinadas secciones del sitio.
- Metaetiquetas “noindex”: Instruyen al bot a no indexar la página, aunque puede seguir sus enlaces.
- Falta de enlaces internos: Si una página no está enlazada desde ninguna otra parte del sitio, el bot no podrá encontrarla fácilmente.
- Velocidad de carga lenta: Páginas que tardan mucho en cargar pueden ser abandonadas antes de ser analizadas por completo.
- Uso excesivo de JavaScript: Algunos contenidos dinámicos no son leídos correctamente por los bots.
Errores 404 o 500: Si una URL devuelve errores, es probable que no sea rastreada ni indexada.
¿Cómo saber si su sitio está indexado?
La indexación es el proceso mediante el cual los motores de búsqueda como Google almacenan páginas web en su base de datos para mostrarlas en los resultados de búsqueda. Si tu sitio no está indexado, simplemente no aparecerá en Google, sin importar cuánto contenido publiques o cuán optimizado esté. A continuación, te mostramos cómo comprobar si tu sitio está indexado y qué hacer si no lo está.
➡️Usa el comando “site:” en Google
Una forma rápida y sencilla:
- Abre Google y escribe en la barra de búsqueda:
site:tu-dominio.com
(Ejemplo:site:midominio.com) - Si ves resultados, significa que tu sitio (o partes de él) están indexados.
- Si no aparece nada, es probable que Google aún no haya indexado tu sitio o haya algún problema técnico.
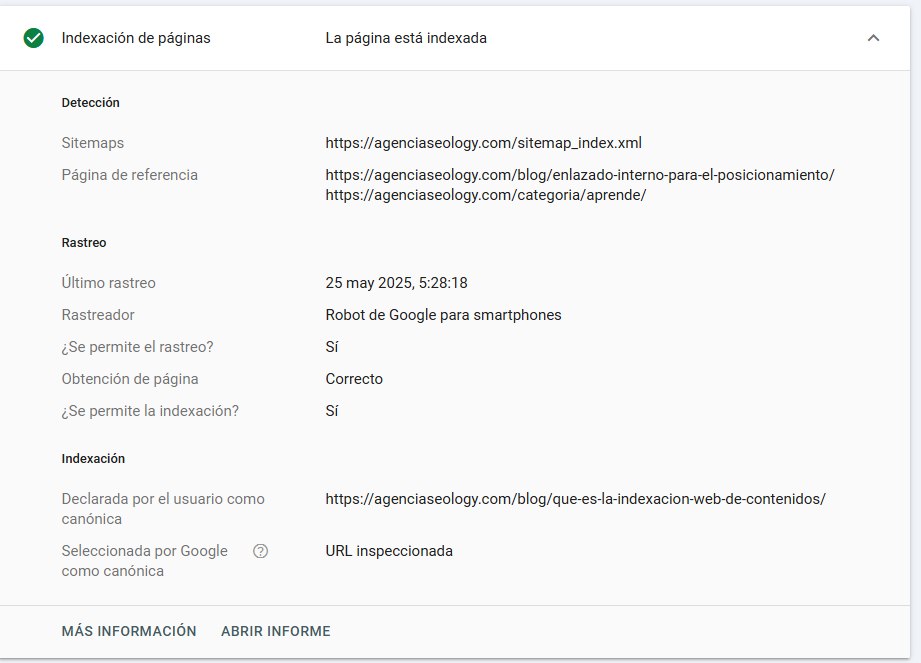
➡️Verifica en Google Search Console
Google Search Console es una herramienta gratuita esencial para webmasters.
Pasos para comprobar la indexación:
- Accede a Google Search Console
- Selecciona tu propiedad (sitio web).
- Usa la barra superior para inspeccionar una URL específica.
- El sistema mostrará si la URL está indexada o no, y el motivo si no lo está.
Además, puedes:
- Revisar el informe de Cobertura del índice, que muestra:
- Páginas válidas indexadas.
- Páginas excluidas (por errores, redirecciones, bloqueos, etc.).
- Errores de rastreo o problemas con el archivo robots.txt.
➡️Revisa los archivos robots.txt y meta-etiquetas
Errores comunes que impiden la indexación:
- Archivo
robots.txtbloqueando el acceso de bots. - Etiquetas
<meta name="robots" content="noindex">en el código fuente de páginas importantes.
Verifica que no estés deshabilitando el rastreo o la indexación de forma accidental.
➡️Utiliza herramientas de análisis SEO
Algunas herramientas que pueden ayudarte a evaluar el estado de indexación:
Estas herramientas ofrecen reportes técnicos y alertas sobre problemas de indexación, etiquetas noindex o errores de rastreo.
➡️¿Qué hacer si tu sitio no está indexado?
Si tu sitio no aparece en los resultados de búsqueda:
- Solicita la indexación manual desde Google Search Console.
- Corrige errores técnicos detectados en el rastreo (por ejemplo, redirecciones incorrectas o contenido duplicado).
- Asegúrate de tener contenido único y de valor.
- Crea enlaces internos y externos que apunten a las páginas importantes para facilitar la detección por los bots.
Herramientas para analizar la Crawlability
Existen varias herramientas que permiten evaluar la capacidad de rastreo de un sitio web y detectar posibles problemas.
Herramienta | Descripción | Características |
Aplicación de escritorio que rastrea sitios web como lo haría un bot de los motores de búsqueda. | Análisis profundo de enlaces internos, redirecciones, errores 404, meta datos, arquitectura de sitio, exportación a Excel. | |
Herramienta de auditoría SEO visual con un enfoque en la usabilidad de los datos. | Mapas visuales del crawl, auditorías técnicas, insights detallados, soporte para JavaScript y análisis de estructura. | |
Plataforma basada en la nube para rastreo, análisis de logs y rendimiento técnico SEO. | Análisis de crawlability y log files, detección de cuellos de botella, visualización de la estructura del sitio. | |
Plataforma SEO técnica empresarial centrada en la escalabilidad. | Rastreos programados, seguimiento de cambios, colaboración en equipo, visualización de estructura, análisis de JavaScript. | |
Plataforma SEO técnica que combina datos de rastreo y log files. | Segmentación avanzada, análisis de JavaScript, integración con Google Data Studio, análisis de rendimiento de crawl. | |
Plataforma de gestión de calidad web centrada en la optimización técnica. | Auditoría técnica SEO, rastreo inteligente, alertas, integración con Google Search Console. | |
Herramienta de SEO para Windows que permite el análisis técnico del sitio. | Rápido rastreo local, búsqueda de errores técnicos, análisis de duplicados y estructura de sitio. | |
Herramienta gratuita de Google para monitorear y mantener la presencia del sitio en los resultados de búsqueda. | Informe de cobertura, inspección de URL, estadísticas de rastreo, bloqueos de robots.txt. | |
Parte del conjunto de herramientas SEO de Ahrefs centrado en auditorías técnicas. | Rastreos basados en la nube, informe de salud del sitio, detección de problemas de rastreo y accesibilidad. | |
Herramienta técnica integrada dentro del ecosistema de Semrush. | Informes personalizables, detección de problemas de crawlability, auditorías programadas, seguimiento de errores. |
Factores que afectan la Crawlability
Existen varios factores que pueden influir en la capacidad de rastreo de un sitio web. Algunos de los más importantes incluyen:
➡️Archivo Robots.txt
El archivo robots.txt es uno de los primeros archivos que los bots consultan al llegar a un sitio. Este documento indica a los motores de búsqueda cuáles páginas o directorios pueden o no pueden rastrear.
🔰Problemas comunes:
- Bloqueo accidental de páginas importantes (como el blog o el directorio de productos).
- Uso excesivo del comando Disallow, lo que limita innecesariamente el acceso de los bots.
🔰Buenas prácticas:
- Revisa regularmente el archivo robots.txt.
- Permite el acceso a los recursos necesarios para renderizar correctamente tu sitio (CSS, JS).
- Utiliza herramientas como Google Search Console para verificar errores de rastreo relacionados.
➡️Etiquetas Meta Robots
Las metaetiquetas robots permiten controlar el comportamiento de los bots a nivel de página individual. Puedes usar directivas como noindex, nofollow, noarchive, entre otras.
🔰Impacto en la crawlability:
- La directiva noindex impide que una página se incluya en el índice, aunque pueda ser rastreada.
- nofollow evita que los bots sigan los enlaces de esa página, lo que puede afectar la exploración del sitio.
🔰Buenas prácticas:
- Aplica noindex solo a páginas que realmente no aportan valor al buscador (como carritos de compra o páginas duplicadas).
- Evita combinar noindex con nofollow si deseas que los bots sigan descubriendo contenido a través de los enlaces.
➡️Estructura de enlaces internos
Los enlaces internos son fundamentales para guiar a los bots a través del contenido de un sitio. Una buena arquitectura de enlaces facilita el rastreo y mejora la distribución del PageRank interno.
🔰Problemas frecuentes:
- Páginas huérfanas (sin enlaces internos que apunten a ellas).
- Estructura poco jerárquica o enlaces ocultos en menús desplegables.
🔰Recomendaciones:
- Asegúrate de que todas las páginas relevantes estén enlazadas desde otras partes del sitio.
- Utiliza una estructura jerárquica clara, con categorías, subcategorías y enlaces contextuales.
- Incluye enlaces en el footer o en el sitemap HTML para facilitar el rastreo.
➡️Errores de servidor (5xx)
Los errores del servidor, como los códigos 500, 502 o 503, indican que el sitio no está disponible temporalmente. Si un bot encuentra estos errores con frecuencia, podría reducir la frecuencia de rastreo o evitar visitar el sitio.
🔰Consecuencias:
- Pérdida de oportunidades de indexación.
- Disminución de la confianza del bot en la estabilidad del sitio.
🔰Prevención:
- Monitoriza la salud del servidor con herramientas como Google Search Console, Screaming Frog o logs de acceso.
- Usa servicios de alojamiento confiables con buen tiempo de actividad.
- Configura respuestas 503 con retry-after si el sitio está en mantenimiento.
➡️Velocidad de carga
Los bots tienen un presupuesto de rastreo limitado por sitio. Esto significa que si las páginas tardan demasiado en cargar, el bot podría abandonar el rastreo antes de analizar todo el contenido.
🔰Factores que afectan la velocidad:
- Recursos no optimizados (imágenes grandes, JS excesivo).
- Hosting lento o mal configurado.
- Falta de uso de caché o CDN.
🔰Consejos de optimización:
- Comprime y optimiza imágenes.
- Usa carga diferida (lazy loading) para contenido no crítico.
- Minimiza el uso de scripts y CSS innecesarios.
➡️Contenido duplicado
El contenido duplicado puede generar confusión en los motores de búsqueda, ya que no saben qué versión rastrear e indexar.
🔰Causas comunes:
- URLs con parámetros que generan contenido similar.
- Versiones HTTP y HTTPS o con y sin “www” accesibles al mismo tiempo.
- Copia exacta del contenido en distintas URLs (por ejemplo, versiones impresas).
🔰Soluciones:
- Usa la etiqueta <link rel=”canonical”> para indicar la versión preferida de una página.
- Configura redireccionamientos 301 entre versiones duplicadas.
- Agrupa parámetros similares con la herramienta de parámetros en Search Console.
➡️Uso de JavaScript
Muchas páginas modernas dependen del JavaScript para mostrar contenido dinámico. Sin embargo, no todos los bots ejecutan JS con la misma eficacia.
🔰Riesgos para el rastreo:
- Contenido que aparece solo tras la interacción del usuario (como botones o pestañas).
- Enlaces generados con JS que los bots no pueden seguir.
- Aplicaciones SPA (Single Page Application) mal configuradas.
🔰Recomendaciones:
- Usa renderizado estático o hidración progresiva para sitios JS.
- Asegura que el contenido clave esté visible en el HTML inicial.
- Verifica con herramientas como la inspección de URL en Google Search Console si el contenido JS es rastreable.
¿Cómo mejorar la Crawlability de un sitio web?

Para optimizar la capacidad de rastreo de un sitio web, es recomendable seguir algunas prácticas importantes que ya mencionamos de manera general más arriba, pero acá te las detallamos todas.
1️⃣Revisar el Archivo Robots.txt
El archivo robots.txt es un fichero de texto que se coloca en la raíz del dominio y sirve para dar instrucciones a los bots sobre qué partes del sitio pueden o no pueden rastrear. Un error en este archivo puede impedir que los motores de búsqueda accedan a contenido importante.
Pasos para revisar y optimizar el archivo robots.txt:
- Ubicación: Verifica que el archivo esté en
tusitio.com/robots.txt. - Contenido: Asegúrate de que no haya reglas que bloqueen recursos o páginas esenciales para el SEO. Ejemplo negativo:
User-agent: *Disallow: /
Este ejemplo impide que cualquier bot acceda a cualquier parte del sitio. - Revisar en Google Search Console:
- Ve a la herramienta de “Inspección de URL”.
- Introduce una página específica y verifica si está bloqueada por
robots.txt.
- Actualizar el archivo: Si identificas errores, modifícalo y vuelve a subirlo al servidor.
2️⃣Optimizar la estructura de enlaces internos
El enlazado interno ayuda a los motores de búsqueda a entender la jerarquía del sitio y a distribuir la autoridad de las páginas.
Prácticas recomendadas:
- Jerarquía clara: Usa una estructura en forma de pirámide: Home > Categorías > Subcategorías > Páginas de producto.
- Enlaces contextuales: Dentro del contenido, enlaza hacia otras páginas relacionadas de forma natural.
- Anchor text relevante: Usa texto ancla descriptivo que ayude al bot a entender el contenido de la página destino.
- Evitar enlaces rotos: Usa herramientas como Screaming Frog o Ahrefs para detectar enlaces internos que llevan a páginas inexistentes.
3️⃣Corregir errores de servidor
Los errores 5xx indican fallos del servidor y pueden interrumpir el rastreo de los bots.
Cómo solucionarlos:
- Monitoreo constante: Utiliza herramientas como UptimeRobot, Google Search Console o servicios de monitoreo de hosting.
- Consultar los registros del servidor: Revisa los archivos de log para identificar causas frecuentes de errores.
- Optimizar la configuración del servidor: Asegura que el servidor puede manejar la carga de tráfico y peticiones de bots.
- Revisar las reglas de firewall y CDN: Algunos servicios bloquean bots por error. Verifica que Googlebot y otros estén permitidos.
Transforma tu presencia digital con Agencia Seology
En Agencia Seology diseñamos estrategias integrales orientadas al crecimiento real, combinando asesoría especializada con recursos educativos que empoderan a emprendedores, marcas y profesionales del marketing para tomar decisiones informadas y alineadas con las últimas tendencias del sector.
Nuestro enfoque se basa en la unión de análisis técnico, creación de contenido relevante y optimización continua para lograr una visibilidad sostenida en los motores de búsqueda.
🔍 Entre los servicios destacados de Seology se encuentran:
- Consultoría SEO a medida, adaptada a los objetivos específicos de cada proyecto.
- Auditorías SEO profesionales para detectar y corregir problemas técnicos.
- Estrategias SEO para ecommerce, enfocadas en aumentar la visibilidad y conversión de tiendas online.
- Link Building estratégico, con prácticas seguras y efectivas para mejorar tu autoridad.
- SEO local, ideal para negocios que quieren destacar en búsquedas geográficas.
- SEO internacional para empresas que buscan posicionarse en distintos mercados.
- Gestión de migraciones SEO, asegurando que tu tráfico orgánico no se vea afectado.
- Publicidad digital con Google Ads, para atraer tráfico segmentado de manera inmediata.
Accede al contenido especializado de Seology y transforma tu presencia digital en una ventaja competitiva.
Encuentra estrategias SEO para Empresas de Turismo, Ecommerce, Universidades y cualquier otro tipo de industria
¿Necesitas ayuda de expertos SEO en Latinoamérica?
Implementar estas estrategias de forma efectiva marca la diferencia entre el éxito y el estancamiento digital. Si necesitas apoyo profesional, en Seology tenemos presencia en mercados clave: nuestra agencia SEO Colombia atiende empresas que buscan crecer en el mercado colombiano, y nuestra Agencia SEO en Chile impulsa la visibilidad de negocios en el mercado chileno.



