
¿Qué es el archivo robots.txt?
El archivo robots.txt es un archivo de texto utilizado para indicar a los motores de búsqueda qué páginas o secciones de un sitio web pueden rastrear y cuáles no. Se encuentra en la raíz del dominio y sigue el estándar de exclusión de robots, un protocolo que los motores de búsqueda respetan para evitar rastrear contenido innecesario o restringido. El archivo es una herramienta esencial para la optimización del rastreo, ya que dirige a los bots de los motores de búsqueda hacia las páginas más importantes para evitar que gasten recursos en contenido irrelevante o duplicado. Acá tienes un ejemplo breve sobre cómo funciona:
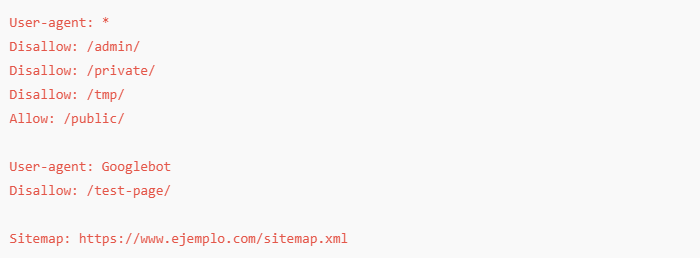
Explicación del archivo robots.txt:
✅ User-agent: * – Aplica estas reglas a todos los motores de búsqueda. ✅ Disallow: /admin/ – Evita que los bots rastreen la carpeta /admin/. ✅ Disallow: /private/ – Bloquea el acceso a la carpeta /private/. ✅ Disallow: /tmp/ – Impide el rastreo de archivos temporales en /tmp/. ✅ Allow: /public/ – Permite el acceso a la carpeta /public/. ✅ User-agent: Googlebot – Aplica reglas específicas para el bot de Google. ✅ Disallow: /test-page/ – Evita que Google rastree la página /test-page/. ✅ Sitemap – Proporciona la URL del sitemap para mejorar la indexación en los motores de búsqueda.
¿Cómo funciona el archivo robots.txt?
Los motores de búsqueda, como Google, Bing y Yahoo, envían bots para rastrear sitios web y agregar contenido a sus índices. Antes de acceder a un sitio, los bots revisan el archivo robots.txt para determinar qué secciones pueden explorar y cuáles deben evitar. El robots.txt se estructura en reglas que especifican permisos o restricciones para los bots. Cada regla se compone de dos partes principales:
- User-agent: Indica a qué bot se dirige la regla. Puede aplicarse a todos los bots o a uno en específico.
- Disallow / Allow: Define qué partes del sitio pueden o no pueden ser rastreadas.
Sintaxis básica del archivo robots.txt
El archivo robots.txt sigue una sintaxis sencilla que permite establecer reglas específicas. Algunos ejemplos comunes incluyen:
Permitir el rastreo de todo el sitio
User-agent: *
Disallow:
Es un código que indica que todos los bots pueden rastrear todas las páginas del sitio.
Bloquear el acceso a todo el sitio
User-agent: *
Disallow: /
Con esta configuración, ningún bot podrá rastrear el contenido del sitio.
Bloquear una carpeta específica
User-agent: *
Disallow: /privado/
Aquí se impide el rastreo de la carpeta “privado” y todo su contenido.
Permitir el rastreo de una página dentro de una carpeta bloqueada
User-agent: *
Disallow: /privado/
Allow: /privado/pagina-permitida.html
Se bloquea la carpeta “privado”, pero se permite el rastreo de la página “pagina-permitida.html”.
Bloquear solo a un bot específico
User-agent: Googlebot
Disallow: /seccion-bloqueada/
Esta regla impide que Googlebot rastree la carpeta “seccion-bloqueada”, pero otros bots podrán acceder a ella.
Robots.txt y su impacto en el SEO
El archivo robots.txt tiene un papel importante en la estrategia SEO, ya que influye en la forma en que los motores de búsqueda acceden para indexar un sitio web.
Control del presupuesto de rastreo
Cada motor de búsqueda tiene un límite de páginas que puede rastrear en un sitio web en un período determinado. Este límite se conoce como presupuesto de rastreo. Un archivo robots.txt bien configurado ayuda a optimizar el presupuesto al evitar que los bots desperdicien recursos en páginas irrelevantes, como páginas de administración o contenido duplicado.
Evitar la indexación de contenido no deseado
Aunque el archivo robots.txt no impide directamente la indexación de una página, sí evita que los bots la rastreen. Esto es útil para restringir el acceso a páginas que no deben aparecer en los resultados de búsqueda, como páginas de inicio de sesión o contenido temporal. Para evitar la indexación de una página de manera más efectiva, se recomienda combinar el uso de robots.txt con la etiqueta meta “noindex” en el código HTML de la página.
Protección de información sensible
El archivo puede utilizarse para bloquear el acceso a directorios o archivos que contienen información confidencial, como datos internos o archivos de configuración. Sin embargo, no debe considerarse un método de seguridad, ya que los archivos bloqueados siguen siendo accesibles si alguien conoce la URL.
¿Cómo verificar si un sitio tiene un archivo robots.txt?
Para comprobar si un sitio web tiene un archivo robots.txt, basta con escribir la URL del sitio seguida de “/robots.txt”. Por ejemplo:
https://www.ejemplo.com/robots.txt
Si el archivo existe, se mostrará su contenido en el navegador. Si no existe, se generará un error 404 o una página en blanco.
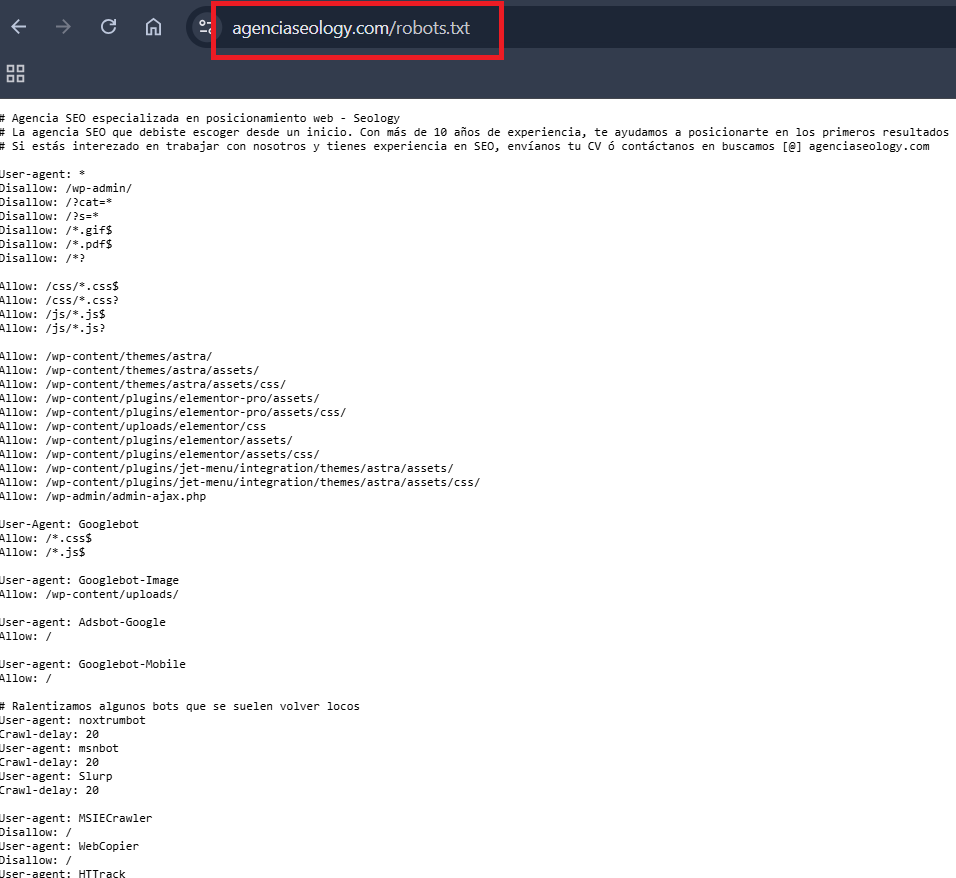
¿Cómo crear y editar un archivo robots.txt?
El archivo robots.txt se puede crear con cualquier editor de texto y debe guardarse con el nombre “robots.txt” en la raíz del dominio. Para editarlo, basta con modificar su contenido y subirlo nuevamente al servidor. Algunos sistemas de gestión de contenido, como WordPress, generan un archivo robots.txt automáticamente, pero también permiten personalizarlo mediante complementos o configuraciones avanzadas.
Errores comunes al configurar robots.txt
Hay algunos errores que se deben evitar a toda costa al configurar robots.txt:
Bloquear contenido importante por accidente
Un error común es bloquear secciones del sitio que deberían ser rastreadas e indexadas, lo que puede afectar negativamente el posicionamiento en los motores de búsqueda.
Usar robots.txt para bloquear contenido ya indexado
El archivo robots.txt impide el rastreo, pero no elimina una página ya indexada. Para evitar que una página aparezca en los resultados de búsqueda, es recomendable usar la metaetiqueta “noindex” o solicitar su eliminación en Google Search Console.
No permitir el rastreo de archivos CSS y JavaScript
Algunos sitios bloquean archivos CSS y JavaScript en su archivo robots.txt, lo que puede dificultar el correcto renderizado de las páginas y afectar la experiencia del usuario. Google recomienda permitir el acceso a estos archivos para garantizar una correcta indexación.
¿Cómo probar y validar un archivo robots.txt?
Para verificar que el archivo robots.txt está configurado correctamente, se pueden utilizar herramientas como:
- Google Search Console: Proporciona una herramienta de prueba de robots.txt que permite verificar si las reglas están funcionando como se espera.
- Herramientas de terceros: Existen diversas herramientas en línea que permiten analizar y validar un archivo robots.txt.
Alternativas y complementos a robots.txt
Además del archivo robots.txt, existen otras formas de controlar el rastreo e indexación de un sitio web:
- Metaetiqueta “robots”: Se agrega en el código HTML de una página para indicar si debe ser indexada o no.
- X-Robots-Tag: Permite controlar la indexación de archivos específicos, como imágenes o documentos PDF.
- Canonicals: Ayudan a evitar problemas de contenido duplicado al indicar la versión preferida de una página.
Explorar estas opciones junto con una configuración adecuada del archivo robots.txt puede mejorar la visibilidad y el rendimiento de un sitio web en los motores de búsqueda.
Huevos de Pascua de robots.txt
Los Huevos de Pascua en robots.txt son mensajes ocultos o divertidos que los desarrolladores agregan al archivo robots.txt de un sitio web. No afectan el SEO ni la indexación, pero sorprenden a quienes los descubren.
Solo echa un vistazo a lo que dice el el archivo robots.txt de Youtube: “Creado en un futuro lejano (el año 2000) después del levantamiento robótico de mediados de los 90 que acabó con todos los humanos.” O el robots.txt de Nike dice “just crawl it” (un guiño a su eslogan “just do it”) y también incluye su logotipo.
Encuentra estrategias SEO para Centros Estéticos, E Commerce, Universidades y cualquier otra industria. Sigue aprendiendo sobre SEO y marketing digital con todo lo que tenemos que ofrecerte en nuestra Agencia SEO; te invito a leer más contenido interesante en nuestro blog.
Lleva tu estrategia SEO al siguiente nivel
Implementar estas estrategias de forma efectiva marca la diferencia entre el éxito y el estancamiento digital. Si necesitas apoyo profesional, en Seology tenemos presencia en mercados clave: nuestra agencia SEO Colombia atiende empresas que buscan crecer en el mercado colombiano, y nuestra Agencia SEO en Chile impulsa la visibilidad de negocios en el mercado chileno.



