
Estábamos haciendo una auditoría para un cliente nuevo (un e-commerce del sector salud con años en el mercado). Al entrar al sitio, visualmente todo se veía correcto. Buen diseño, productos bien organizados. Pero al correr Screaming Frog con la configuración adecuada, lo que encontramos fue difícil de ignorar: 263 URLs con contenido semiduplicado. Varias páginas con contenido idéntico al 100%. Y para rematar, algunas con texto en latín - placeholder de una plantilla que nadie eliminó y que Google lleva meses rastreando como si fuera contenido real.
Lo interesante no es que el problema existiera. Es que Screaming Frog, con su configuración por defecto, no lo detecta. Hay que activar una opción específica que la mayoría de personas ignora. Eso es lo que te voy a mostrar hoy.
Por qué el contenido duplicado le hace tanto daño a tu posicionamiento
Cuando Google encuentra múltiples páginas con el mismo contenido, no sabe cuál mostrar en los resultados. Su solución es simple y brutal: las devalúa todas, o directamente las desindexar.
Esto tiene dos consecuencias concretas:
- Pierdes presupuesto de rastreo. Googlebot tiene un tiempo limitado para rastrear tu sitio. Cada URL duplicada que rastrea es tiempo que no invierte en tus páginas importantes.
- Diluyes tu autoridad. En lugar de concentrar todas las señales de posicionamiento en una URL, las repartes entre varias versiones del mismo contenido. Ninguna termina posicionando bien.
Lo vimos con otro cliente, en el sector retail: decenas de fichas de producto duplicadas al 100% terminaron desindexadas automáticamente. El tráfico no cayó de un día para otro - fue una caída silenciosa que tomó meses detectar porque nadie sabía qué estaba pasando.
Ojo con los e-commerce: tener un 90–95% de similitud entre páginas de un mismo producto en tallas o colores distintos puede ser aceptable si se maneja con canonicals. Pero un 100% de coincidencia entre URLs diferentes es una señal de problema real - no hay ninguna razón válida para que dos páginas distintas tengan exactamente el mismo contenido.
La configuración que casi nadie activa en Screaming Frog
Por defecto, Screaming Frog solo detecta duplicados exactos. Para que también identifique contenido casi idéntico - que es donde está la mayoría de los problemas - hay que activar la detección de semiduplicados manualmente.
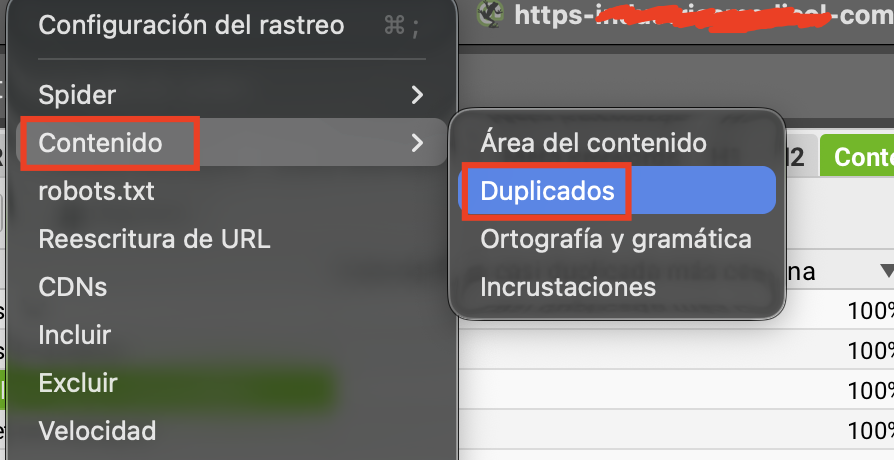
Paso 1: Ir a la configuración correcta
Con Screaming Frog abierto, ve a Configuración del rastreo // Contenido // Duplicados. Esta sección no aparece en el menú principal - tienes que buscarla dentro de las opciones de contenido del spider.
 Contenido > Duplicados - Seology”/>
Contenido > Duplicados - Seology”/>
La opción de duplicados está dentro de Configuración del rastreo → Contenido. No viene activada por defecto.
Paso 2: Activar los semiduplicados y definir el umbral
Dentro de esa pantalla, activa estas dos opciones:
- ✅ Comprobar solo páginas indexables para duplicados: filtra páginas que Google no debería estar rastreando de todas formas.
- ✅ Activar semiduplicados: sin esto, la herramienta solo detecta coincidencias exactas del 100% y se pierde todo lo demás.
En Umbral de similitud (%), coloca 20. Esto le dice a Screaming Frog que marque cualquier par de páginas que compartan el 20% o más de contenido. Es un umbral bajo a propósito - mejor que sobre, para no perderse nada.
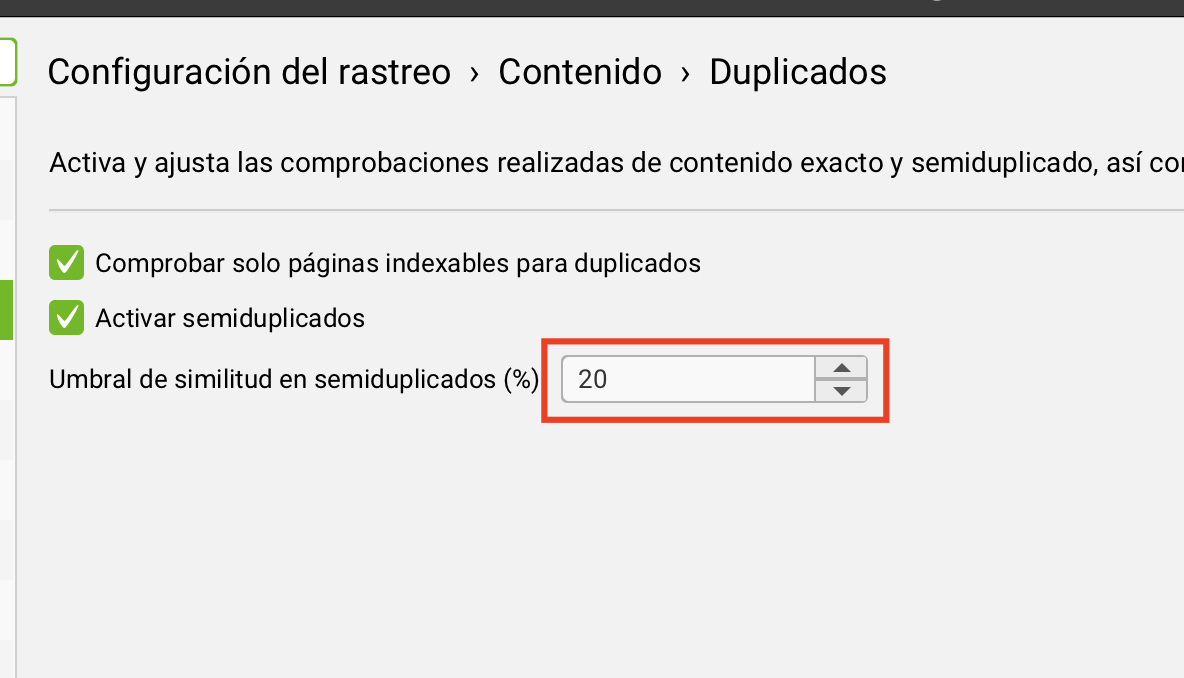
Las dos casillas deben estar activas y el umbral en 20% para detectar toda la gama de duplicidad posible.
Paso 3: Correr el rastreo y el análisis de similaridad
Corre el rastreo normalmente. Cuando termine al 100%, hay un paso que la mayoría omite: ve a la pestaña Análisis de rastreo e inicia el análisis de similaridad. Es un proceso corto - segundos o pocos minutos según el tamaño del sitio - pero sin él, las columnas de duplicados aparecen vacías.
Una vez terminado, ve a la pestaña Contenido del rastreo. En el panel lateral derecho verás el resumen: duplicados exactos, semiduplicados, páginas con poco contenido. En nuestro caso: 263 semiduplicados.
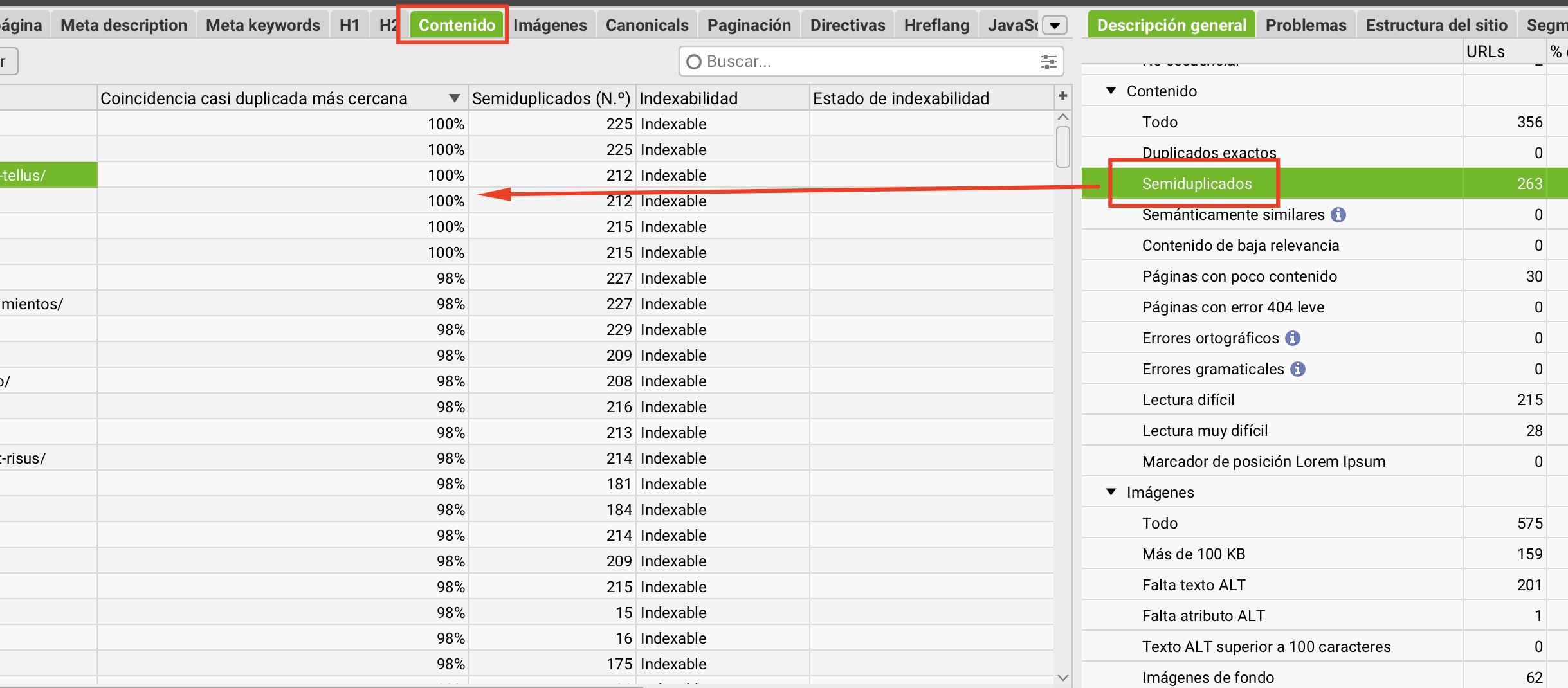
El panel de la derecha muestra el resumen de problemas. 263 semiduplicados es una señal de alerta importante para cualquier sitio.
Cómo leer los detalles de cada duplicado
En la tabla central verás la columna Coincidencia casi duplicada más cercana, con porcentajes del 0 al 100%. Cuanto más cerca del 100%, más idéntico es el contenido.
Para ver exactamente con qué URL se está duplicando una página y qué contenido se repite:
- Selecciona la URL en la tabla.
- En el panel inferior, abre la pestaña Detalles de duplicados.
- Verás la URL duplicada, el porcentaje de coincidencia y una previsualización lado a lado del contenido repetido.
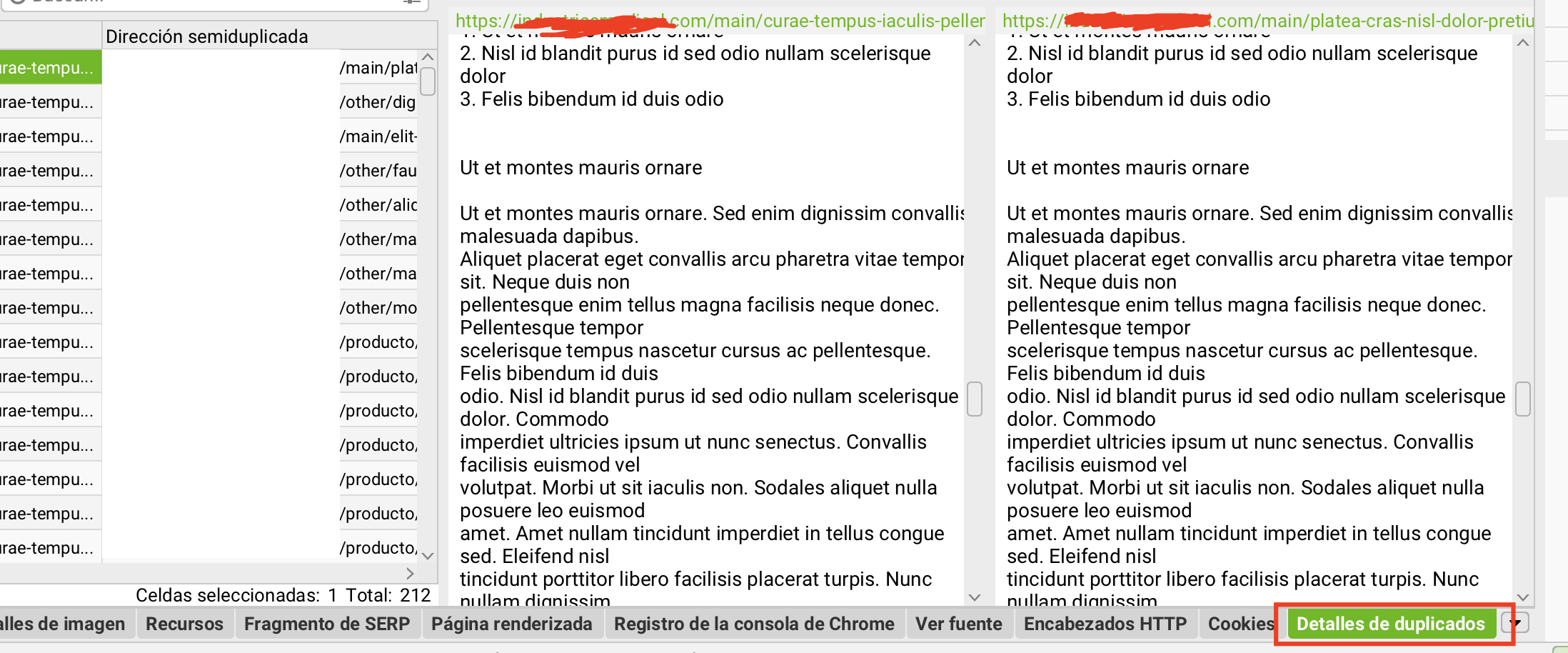
La vista de detalles muestra exactamente qué fragmento de contenido se está repitiendo entre dos URLs. En este caso: fichas de producto idénticas al 100% en un e-commerce.
¿Qué hacer cuando encuentras el problema?
La solución depende del origen:
- Fichas de producto con variantes (talla, color, material): implementar etiquetas canonical apuntando a la URL principal del producto. No elimines las variantes - solo indícale a Google cuál es la versión que debe indexar.
- Páginas de categorías con textos similares: diferenciar los contenidos. Un cambio en el título no es suficiente - el cuerpo del texto también tiene que ser distinto.
- Contenido placeholder o de plantilla: eliminarlo sin excepciones. Google no debería estar rastreando texto que no le aporta nada al usuario.
- Páginas de paginación: configurar los parámetros de URL en Google Search Console para que no se traten como páginas independientes.
La clave no es solo encontrar el problema. Hay que entender por qué se generó. Si es un e-commerce con miles de productos, probablemente necesitas una solución sistemática, no página por página. Si es contenido de plantilla, es un error de implementación que alguien tiene que corregir en el CMS.
Encuentra en Seology servicios de auditoría SEO técnica para detectar estos y otros problemas que frenan el posicionamiento de tu sitio.
